
Gemma 是一系列轻量级、最先进的开放模型,采用与创建 Gemini 模型相同的研究和技术而构建。 Gemma 由 Google DeepMind 和 Google 的其他团队开发,其灵感来自 Gemini,其名称反映了拉丁语 gemma,意思是“宝石”。除了我们的模型权重之外,我们还发布了工具来支持开发人员创新、促进协作并指导负责任地使用 Gemma 模型。
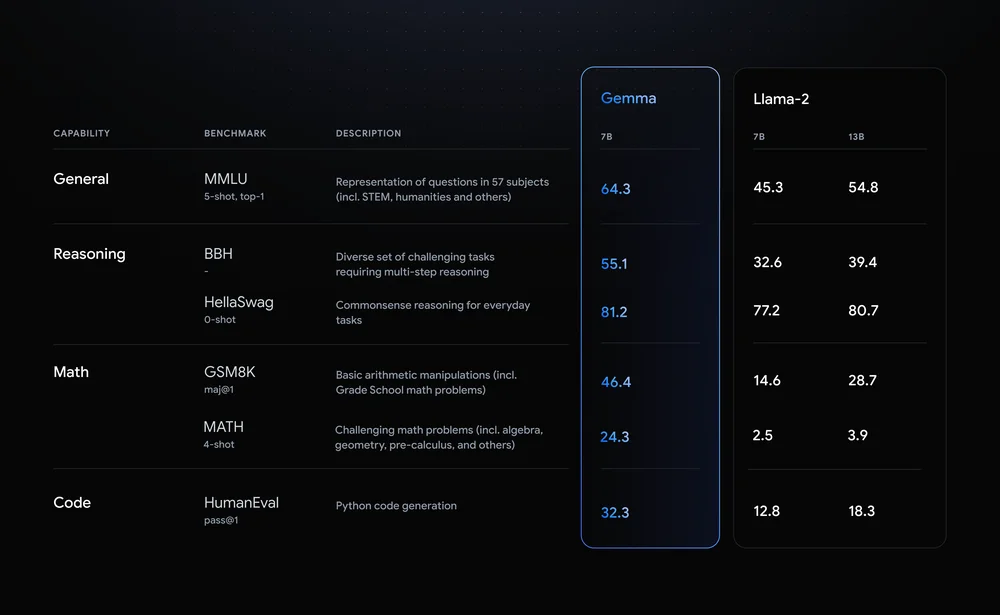
Gemma 模型与 Gemini 共享技术和基础设施组件,Gemini 是我们当今广泛使用的最大且功能最强大的 AI 模型。与其他开放式型号相比,这使得 Gemma 2B 和 7B 能够在其尺寸范围内实现同类最佳的性能。 Gemma 模型能够直接在开发人员笔记本电脑或台式计算机上运行。值得注意的是,Gemma 在关键基准上超越了更大的模型,同时遵守我们安全和负责任的输出的严格标准。有关性能、数据集组成和建模方法的详细信息,请参阅技术报告。
如何安装
- 下载安装ollama 客户端: 【点击下载】
2.打开power shell, 运营安装命令。普通7B版 安装指令:(适合8G显存)
ollama run gemma:7b
3. 7B的全量版本:(需要16G左右的显存)
ollama run gemma:7b-instruct-fp16
4. 2B轻量版:(适合CPU会低配电脑安装)
ollama run gemma:2b